
")
İnsanlık yararına kullanıldığında çok önemli başarılar elde edebilecek veri madenciliği kontrol edilemediğinde ürkütücüdür. Büyük veri üzerinde analiz yapan tüm şirketlerin ve kamu kurumlarının, özerk kamu kurumları tarafından denetlenmesi gerekir. İnsanlar kendilerinden zorla alınan ya da gönüllü olarak saçtıkları verileri sorgulamaya başlamadıkça gelecek pek parlak görünmüyor…
5 Şubat 2014 tarihinde mecliste kabul edilen yeni internet yasasının en önemli gerekçelerinden biri özel hayatın korunmasıydı. Bu yeni düzenlemeyle, “özel hayatının gizliliğinin ihlal edildiğini iddia eden kişiler, Başkanlığa (Telekomünikasyon İletişim Başkanlığı) doğrudan başvurarak içeriğe erişimin engellenmesi tedbirinin uygulanmasını isteyebilir.”
Ancak iddia edilenin aksine yeni düzenleme özel hayatın ihlali konusunda önemli riskler içeriyor. 5651 sayılı yasanın eski halinde erişim sağlayıcılar, sağladıkları “hizmetlere ilişkin, yönetmelikte belirtilen trafik bilgilerini altı aydan az ve iki yıldan fazla olmamak üzere yönetmelikte belirlenecek süre kadar saklamakla ve bu bilgilerin doğruluğunu, bütünlüğünü ve gizliliğini sağlamakla” yükümlüydüler. Yeni düzenlemede ise yer sağlayıcıların “yer sağladığı hizmetlere ilişkin trafik bilgilerini bir yıldan az ve iki yıldan fazla olmamak üzere yönetmelikte belirlenecek süre kadar saklama”sı da eklendi. Fakat daha da önemlisi, “Başkanlığın talep ettiği bilgileri talep edilen şekilde Başkanlığa teslim etme” yükümlülüğü getirildi. Böylece özel hayatı koruyayım derken internet kullanıcıları için daha ciddi bir tehdit ortaya çıktı. Trafik bilgisi kanununda, “internet ortamında gerçekleştirilen her türlü erişime ilişkin olarak taraflar, zaman, süre, yararlanılan hizmetin türü, aktarılan veri miktarı ve bağlantı noktaları gibi değerleri” ifade ediyor. Saklanan ve talep edildiği taktirde teslim edilmesi gereken trafik bilgileri çok masumane görünüyor.
 Sıradan gibi görünen bu bilgi çeşitli kullanım pratiklerine bakıldığında son derece kritik olabiliyor. Trafik bilgisi sadece suç durumunda istenecek bir bilgi, kişisel verilerin gizliliğini koruyan özerk kurumlarımız ve kişisel verilerin gizliliğine duyarlı bir kamuoyumuz olsaydı bu düzenleme nedeniyle çok fazla endişelenmemize gerek yoktu. Belki de bu düzenlemeyi yapanların tek amacı şimdilik sadece suç durumunda trafik bilgisine başvurmak. Ama kişisel verilerin gizliliğini koruyan özerk kurumlar olmadan bu düzenleme şimdi olmasa bile sonrası için büyük risk taşıyor.
Sıradan gibi görünen bu bilgi çeşitli kullanım pratiklerine bakıldığında son derece kritik olabiliyor. Trafik bilgisi sadece suç durumunda istenecek bir bilgi, kişisel verilerin gizliliğini koruyan özerk kurumlarımız ve kişisel verilerin gizliliğine duyarlı bir kamuoyumuz olsaydı bu düzenleme nedeniyle çok fazla endişelenmemize gerek yoktu. Belki de bu düzenlemeyi yapanların tek amacı şimdilik sadece suç durumunda trafik bilgisine başvurmak. Ama kişisel verilerin gizliliğini koruyan özerk kurumlar olmadan bu düzenleme şimdi olmasa bile sonrası için büyük risk taşıyor.
1990’lardan itibaren BT’nin (bilişim teknolojileri) ilerlemesiyle beraber çok çeşitli konularda ve çeşitli amaçlar için veri depolanıyor (Bramer, 2013):
– Şu anki NASA Earth gözlem uyduları günde 1 terabayt veri oluşturuyor. Bu, daha önceki gözlem uydularının verisinin toplamından daha fazla.
– İnsan Genom Projesi milyarlarca genetik temel için binlerce bayt veri kaydediyor.
– Birçok şirket müşteri işlemlerini takip etmek için geniş veri ambarları oluşturdu. Küçük bir veri ambarı bile yüz milyondan fazla müşteri işlemi içeriyor.
– Kredi kartı işlemleri, telefon kayıtları, web’deki trafik bilgileri, CCTV kayıtları olağanüstü hacimlerde.
– 650 milyondan fazla web sitesi var.
– 900 milyondan fazla Facebook kullanıcısı var ve günde ortalama 3 milyar mesaj atılıyor.
– Twitter’ın 150 milyondan fazla kullanıcısı olduğu tahmin ediliyor ve günde ortalama 350 milyon tweet atılıyor.
Şirketler, web’deki her tıklamayı, hatta kimi zaman farenizin her hareketini kaydederek devasa veri dağları oluşturdular. Verilerin birikimi kendiliğinden bir süreç değildi.. Facebook örneğinde olduğu gibi kullanıcı tıklarının yeterli olmadığı fark edildiğinde kullanıcılara kişisel verilerini gönül rahatlığıyla saçabilecekleri sosyal ağlar hazırlandı. Günümüzde şirketler ve hükümetler, oluşturdukları veri dağlarını kazarak altın değerinde bilgiler elde etmeye çalışıyorlar.
Veri toplamanın tarihçesi
Şirketlerin veri toplamaya yönelik bu ilgisi yeni değil. Daha 20. yüzyıl başlarında piyasa araştırmasının babası olarak kabul edilen Charles Coolidge Parlin, reklam için müşteriler ve piyasalar hakkında bilgi toplamanın öneminin farkındaydı. 1923 yılında Arthur C. Nielsen tarafından kurulan ACNielsen şirketi pazarlamacılara, pazarlama ve satış konusunda güvenilir ve nesnel bilgi sunmaktaydı. Hem Parlin hem de Nielsen, piyasadaki eğilimleri tespit edebilmek ve bu eğilimler doğrultusunda kararlar oluşturabilmek için kaliteli veriye sahip olmanın önemini keşfetmişlerdi (Hammergren ve Simon, 2009).
 1970’li yıllarda ana bilgisayarlar (mainframe), iş dünyasına yeni fırsatlar sunmasına rağmen esnek ve hızlı analizler için yeterli değildi. Bu sistemler, rutin sorgularda ve raporlamalarda faydalı olurken müşterilerin harcamaları, tercihleri, satın aldıkları ürünler vb hakkında yanıt almak istenildiğinde yetersiz kalıyordu. Talebin veri işlem birimine iletilmesi, onun bu talebi sıraya koyması gerekiyordu. Birkaç ay sonra istediğiniz bilgiyi (belki!) alabiliyordunuz. Bu gecikme sorunları nedeniyle, zaman zaman ihtiyaç duyulabilecek bir miktar veri teyplerle mini bilgisayarlara kopyalanıp onun üzerinde analizler yapılıyordu. Böylece veri işleme merkezlerinin yükü biraz hafiflemiş oluyordu. Fakat bir şirketin farklı fiziksel alanlarda birden fazla ana bilgisayarının olduğu durumlarda şirket kararlarına yardımcı olabilecek genel analizler yapma konusunda zorluklar çıkıyordu (age).
1970’li yıllarda ana bilgisayarlar (mainframe), iş dünyasına yeni fırsatlar sunmasına rağmen esnek ve hızlı analizler için yeterli değildi. Bu sistemler, rutin sorgularda ve raporlamalarda faydalı olurken müşterilerin harcamaları, tercihleri, satın aldıkları ürünler vb hakkında yanıt almak istenildiğinde yetersiz kalıyordu. Talebin veri işlem birimine iletilmesi, onun bu talebi sıraya koyması gerekiyordu. Birkaç ay sonra istediğiniz bilgiyi (belki!) alabiliyordunuz. Bu gecikme sorunları nedeniyle, zaman zaman ihtiyaç duyulabilecek bir miktar veri teyplerle mini bilgisayarlara kopyalanıp onun üzerinde analizler yapılıyordu. Böylece veri işleme merkezlerinin yükü biraz hafiflemiş oluyordu. Fakat bir şirketin farklı fiziksel alanlarda birden fazla ana bilgisayarının olduğu durumlarda şirket kararlarına yardımcı olabilecek genel analizler yapma konusunda zorluklar çıkıyordu (age).
1980’lerde veritabanı teknolojilerindeki ilerlemelere paralel olarak analistler, veritabanlarına ve dosyalara doğrudan erişimi tercih etmeye başladılar. Fakat 1980’lerin sonlarına doğru IBM araştırmacıları Barry Devlin ve Paul Murphy’nin geliştirdiği “iş veri ambarı” kavramı ile 1970’lere geri dönüldü. Veri ambarları, 1970’lerde denenen, işlem ve analiz birimlerini ayırmayı hedefleyen stratejinin daha geliştirilmiş ve doğru zamanda uygulanan bir haliydi. Veri ambarlarıyla, farklı yerlerdeki veriler uygun bir biçimde saklanarak ve bir araya getirilerek veri işleyen birimleri yormadan analiz edilebiliyordu (age). Veri ambarları,
– şirketlerin işleriyle ilgili stratejik kararlarda,
– şirket içinde birimler arası işbirliğinin geliştirilmesine,
– piyasadaki genel eğilimlerin tespit edilmesinde,
– müşterilerin davranış ve eğilimlerinin belirlenmesinde
etkili oldu. Şirketler veriyi bilgiye, bilgiyi de kâra dönüştürebileceklerini gördüler. Kâr hırsı veri açlığını tetikledi ve akla gelebilecek her konuda veri ambarları oluşturmaya giriştiler.
2000’li yıllara gelindiğinde:
– Bilgisayarların işlem gücü ve depolama kapasiteleri muazzam boyutlara ulaşmıştı
– Hem internetten hem de kurumsal ağlardan sürekli veri akışı vardı.
– Veri analiz teknikleri ilerlemişti.
– Birçok şirketin kurumsal veri ambarları vardı.
– Şirketler, verilerden elde ettikleri bilgileri müşteri ilişkileri yönetiminde kullanarak rekabet güçlerini artırmaya çalışıyorlardı.
İşte veri madenciliği bu tarihsel koşullarda giderek daha önemli hale gelmekteydi. MIT Technology Review, Ocak 2001 sayısında veri madenciliğini dünyayı değiştirecek on yeni teknolojiden biri olarak görüyordu (http://www2.technologyreview.com/featured-story/400868/emerging-technologies-that-will-change-the-world/).
11 Eylül 2001 sonrası dönem
11 Eylül 2001 ise veri analizi konusunda önemli bir dönüm noktası oldu. Westphal’a (2008) göre 11 Eylül’ün sinyalleri önceden verilmiş, verilerin dünyasında sıra dışı gelişmeler yaşanmış, ama fark edilememişti. ABD’ye öğrenci vizesiyle girmiş birinin ticari havacılık kursu alması olağan bir durum değildi. Hele bu kişinin bazı bilinen teröristlerle dolaylı bağlantılarının olması yeterince kuşku uyandırıcıydı. Bill Clinton, 6 Kasım 2002’de yaptığı konuşmada 11 Eylül saldırganlarının beşinin daha önceden FBI veritabanlarında bulunduğunu söylüyordu. Örneğin bu saldırganlardan biri sadece iki yıldır ABD’de olmasına rağmen 30 kredi kartına sahipti. Saldırganların elebaşı olarak görülen Muhammed Atta’nın 12 evi vardı. Clinton’a göre tüm bunlar kuşkulanılması gereken verilerdi (Larose, 2005).
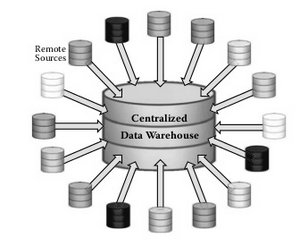
11 Eylül sonrası dönemde büyük resmi görebilmek için kurumlar arası veri paylaşımının gerekli olduğu fark edildi. İlk başta tüm veri kaynaklarından gelen verilerin merkezi bir yere kopyalanması düşünüldü:
Fakat böyle bir mimari çok karışık ve pahalı olacağı gibi ölçeklenebilirlik konusunda da sorunlar yaşanabilirdi. Aşağıdaki gibi dağıtık bir mimari daha uygun olacaktı (Westphal, 2008):
 Her iki mimarinin kendine özgü avantajları ve dezavantajları var. Gereksinimlere ve diğer şartlara göre farklı mimariler tercih edilebilir. Bir şirket, müşteri ilişkileri yönetimi için merkezi bir veri ambarı mimarisini tercih edebilir. Bir istihbarat servisi ise gerçek zamanlı ve çok fazla kaynaktan beslenen analizler yapmak isteyecektir. Muhtemelen de PRISM skandalı sonrasında gündeme gelen NSA’nın büyük bilişim tekelleriyle olan ilişkisi de bu mimariye sahipti.
Her iki mimarinin kendine özgü avantajları ve dezavantajları var. Gereksinimlere ve diğer şartlara göre farklı mimariler tercih edilebilir. Bir şirket, müşteri ilişkileri yönetimi için merkezi bir veri ambarı mimarisini tercih edebilir. Bir istihbarat servisi ise gerçek zamanlı ve çok fazla kaynaktan beslenen analizler yapmak isteyecektir. Muhtemelen de PRISM skandalı sonrasında gündeme gelen NSA’nın büyük bilişim tekelleriyle olan ilişkisi de bu mimariye sahipti.
Veri madenciliğinin tanımına ve uygulamaların geçmeden önce veri madenciliğinin ne olmadığını belirtmekte fayda var. Veri madenciliği, sizin verileri ve sorgularınızı girdiğiniz, ardından da işinize yarayacak sonuçları aldığınız bir uygulama değil. Westphal (2009) veri madenciliğini çocukların noktaları birleştirdiği etkinliklere benzetiyor. Örneğin aşağıdaki gibi noktalarımız olsun:
 Yandaki sayıları birleştirdiğimizde anlamlı bir resim elde edeceğiz. Bu tarz etkinliklerde çoğu zaman ardışık sayılar ya da harfler kullanılıyor. Ama farklı sayı (ya da harf) dizileri de kullanabiliriz. Noktaları birleştirdikçe resim yavaş yavaş ortaya çıkacak. Çoğu zaman tüm noktaları birleştirmeye gerek kalmadan ne olduğunu anlayabileceğiz. Clinton da eğer 11 Eylül 2001 öncesinde noktaları birleştirmiş olsaydık, şüphelileri yakalayabilirdik diyor. Noktaları birleştirdiğimizde ortaya çıkan ya da çıkmaya başlayan şeklin terörist olduğunu nereden bileceğiz? Terörist imgesine sahip olmadan teröristi nasıl tespit edeceğiz? Üstelik hayat değişkendir. Birinin havacılık kurslarına katılıyor olması şüpheli olabilir, dikkatinizi uçak kursuna katılanlara yöneltebilirsiniz. Ya saldırı farklı bir biçimde ve tamamen farklı araçlarla planlanıyorsa? Ya noktaların bazılarının üzerinde herhangi bir sayı olmasaydı? Gerçek hayatta noktaların üzerinde sayılar da yok… Üstelik kurumlar sahip oldukları verinin ne olduğunun tam olarak bilincinde olmayabilirler. Şekil ancak başka yerlerde bulunan noktaların (verilerin) katılımıyla anlam kazanabilir.
Yandaki sayıları birleştirdiğimizde anlamlı bir resim elde edeceğiz. Bu tarz etkinliklerde çoğu zaman ardışık sayılar ya da harfler kullanılıyor. Ama farklı sayı (ya da harf) dizileri de kullanabiliriz. Noktaları birleştirdikçe resim yavaş yavaş ortaya çıkacak. Çoğu zaman tüm noktaları birleştirmeye gerek kalmadan ne olduğunu anlayabileceğiz. Clinton da eğer 11 Eylül 2001 öncesinde noktaları birleştirmiş olsaydık, şüphelileri yakalayabilirdik diyor. Noktaları birleştirdiğimizde ortaya çıkan ya da çıkmaya başlayan şeklin terörist olduğunu nereden bileceğiz? Terörist imgesine sahip olmadan teröristi nasıl tespit edeceğiz? Üstelik hayat değişkendir. Birinin havacılık kurslarına katılıyor olması şüpheli olabilir, dikkatinizi uçak kursuna katılanlara yöneltebilirsiniz. Ya saldırı farklı bir biçimde ve tamamen farklı araçlarla planlanıyorsa? Ya noktaların bazılarının üzerinde herhangi bir sayı olmasaydı? Gerçek hayatta noktaların üzerinde sayılar da yok… Üstelik kurumlar sahip oldukları verinin ne olduğunun tam olarak bilincinde olmayabilirler. Şekil ancak başka yerlerde bulunan noktaların (verilerin) katılımıyla anlam kazanabilir.
Veri madenciliği süreci ve uygulamaları
Bu bağlamda veri madenciliği, “geniş veri ambarlarında, istatistiksel ve matematiksel teknikler kadar örüntü tanıma teknolojilerini de kullanarak anlamlı ilişkiler, örüntüler ve eğilimler keşfetme sürecidir.” (Gartner’dan aktaran Larose, 2005)
Aşağıdaki şekil, veriden bilgi elde etme sürecini özetlemektedir (Bramer, 2013):

Hemen ilk başta kolayca elde edilebilecek bir bilgiye değil (örneğin bir kullanıcının satın aldığı kitaplar) verilerden doğrudan anlaşılamayacak bir bilgiye (örneğin kullanıcıya hangi kitapların önerilebileceği) ulaşılmaktadır. İlk olarak farklı veri kaynaklarından veriler alınıp entegre edilmekte ve analize hazır hale getirilmektedir. Veri depolarında saklanan bu veriler, bir seçme ve ayıklama işlemine tabi tutulduktan sonra veri madenciliği teknikleri ile anlamlı örüntüler ve ilişkiler elde edilir. Elde edilen örüntülerin ve ilişkilerin yorumlanması kritiktir. Sadece matematik ve istatistik konularında bilgili olan biri örüntüleri ve ilişkileri ortaya çıkarsa bile alanın bilgisine sahip olmadığı için bunları yorumlamakta yetersiz kalacaklardır. Alanın bilgisine sahip olmadan örüntüleri fark etmek bile zordur.
Ancak yazılım projelerinden de öğrendiğimiz gibi bilinmeyene doğru yol alırken doğrusal süreçler yetersiz kalmaktadır. CRISP-DM (Cross-Industry Standard Process for Data Mining – Veri Madenciliği İçin Endüstriler Arası Standart), veri madenciliği sürecini iyileştirmek için altı evreden oluşan, sonuçlar ve gereksinimler doğrultusunda önceki evrelere dönülebilen bir süreç önermektedir.

Birinci evre, işin anlaşılması ve hedeflerin tanımlanmasıdır. Araştırılacak ilişkiler ve eğilimler belirlenir. Araştırmacılar sürecin başında ne aradıklarına karar vermelidirler.
İkinci evrede, araştırmacıların öncelikle ellerindeki veriyi değerlendirmeleri gerekir. Bu değerlendirme sonrası birinci evredeki sonuçlar ve hedefler yeniden gözden geçirilebilir. Ayrıca verinin niteliği de önemlidir. Veri kaynağının bilgileri ne kadar güvenilirdir? Her müşterinin TC kimlik numarası var mıdır ve doğru mudur? Veri alanlarında, veri toplanırken geçersiz verilerin girilmesine izin verilmiş midir?
Üçüncü evre, verilerin daha sonraki evrelerde kullanılmak üzere hazırlanmasıdır. Emek yoğun bir süreçtir. Veriler modelleme araçları için uygun biçimlere getirilir.
Dördüncü evrede, seçilen modelleme teknikleri uygulanır. Sonuçları en uygun hale getirmek için parametreler değiştirilir. Önceki evrelerde olduğu gibi, seçilen modelleme tekniğinin gereksinimlerine göre bir önceki evreye dönüp veriler tekrar hazırlanabilir.
Beşinci evrede, modeli uygulama alanına yerleştirmeden önce modelin kalitesi ve verimli olup olmadığı değerlendirilir. Model, birinci evredeki hedeflerle ne kadar örtüşmektedir? Burada oluşturulan modelin ihtiyaca yanıt verip veremediğine karar verilir. Yanıt olumluysa, sonraki evreye geçilir.
Altıncı evrede, oluşturulan model uygulamaya konulur.
Altın madencilerinin her zaman altın bulamayacağı gibi, veri madencileri de değerli bilgiye erişemeyebilirler. Değerli bir bilgi elde edene kadar çok çaba harcamaları gerekebilir. Çünkü varlığı belirsiz bir bilgi araştırılmaktadır. Ama veri madenciliğinden elde edilen bilgilere bakıldığında bu çabaya değer sonuçlara ulaşılabildiği görülür. Larose (2005) başarılı bir veri madenciliği çalışmasından elde edilebilecekleri altı başlık altında değerlendirmektedir:
Tanımlama: Veri madenciliği, verinin içerdiği eğilimleri ve örüntüleri tanımlayıcı bilgi verir. Örneğin bir anket bir bölgede hükümet partisinin oylarının önceki seçime göre sadece düştüğünü gösterebilir. Veri madenciliği ise bu bölgede yaşayanların büyük bir kısmının esnaf aileleri olduğunu, yeni kredi kartı düzenlemesi nedeniyle satışlarının düştüğünü, bundan da hükümeti sorumlu tuttuklarını açıklayabilir.
Tahmin: Tam kayıtlarla yapılır. İstatistiksel analiz yöntemleriyle belirli durumlara ait verilere dayanarak tahminlerde bulunulur. Örneğin, öğrencilerin deneme sınavlarında aldığı puanlara ve ders notlarına bakarak, geçmiş yılların da analiziyle gerçek sınavda nasıl bir performans gösterebileceği tahmin edilebilir.
Öngörü: Tahmine benzer ama sonuçları belirsiz bir gelecektedir. Hız sınırının 70 km’den 90 km’ye çıkması trafik kazalarını nasıl etkileyecektir? Belirli bir hisse senedinin üç ay sonraki değeri ne olabilir?
Sınıflandırma: Veri madenciliğinin en sık başvurulan uygulamalarından biridir. Aşağıdaki gibi kullanım alanları vardır:
– Dolandırıcılık şüphesi taşıyan kredi kartı işlemlerinin tespiti.
– Verilecek bir kredinin banka açısından risk taşıyıp taşımadığı.
– Bir salgın durumunun olup olmadığı.
– Bir vasiyetnamenin iddia edilen kişi tarafından yazılıp yazılmadığı.
– Belirli mali hareketlerin ya da kişisel davranışların bir terör tehdidi içerip içermediği.
Yukarıdaki sınıflandırmalar yapıldığında bütünün içinden belirli bir sınıflandırma içinde yer alan kişi ya da durumları tespit etmek daha hızlı olacaktır. Örneğin bir kredi kartı işlemi, şüpheli işlemler sınıfına giriyorsa alarma geçilebilir.
Kümeleme: Birbirine benzeyen kayıtların, gözlemlerin ya da nesnelerin gruplanmasıdır. Kümeleme, tahmin, öngörü ya da sınıflandırma gibi bir amaca sahip değildir. Daha önce tanımlanmış sınıfları kullanmaz. Kümelemenin temel amacı benzerleri bir araya getirip ve elemanlarının farklı kümelerde yer alanlarla olan benzerliğini en aza indirmektir. Böylece araştırmacı veri dağılımı hakkında bilgi sahibi olur ve sonraki veri madenciliği süreçleri için hazırlık yapar.
İlişkilendirme: Birbiriyle bağlantılı niteliklerin tespit edilmesidir. En bilineni, alışveriş sitelerinde rastladığımız, “bu ürünü alan şunları da aldı.” başlığı altında yapılan önerilerdir. Market verilerinde, “Cumartesi günü 100 müşteri beyaz peynir aldı ve bunlardan 10 tanesi çikolata da aldı.” verisi iki alışverişi ilişkilendirir. Ama bunun nedeni hakkında bilgi vermez.
Veri madenciliği, müşteri ilişkilerinden istihbarata, sağlık sektöründen spora kadar birçok alanda kullanılmaktadır. Kullanım alanları da gün geçtikçe artmaktadır:
– Uydu görüntülerinin analizinde.
– Organik bileşiklerin analizinde.
– Kredi kartı dolandırıcılıklarının tespitinde.
– Elektrik yükü tahmininde.
– Mali tahminlerde.
– Ürün tasarımında.
– Gayrimenkul değerlendirmede.
– Tıbbi tanılarda.
– Hedefli pazarlamada.
Hatta daha 2002 yılında Ersun Yanal ile yapılan bir röportajda, Yanal’ın verileri nasıl analiz ettiğini görüyoruz (bkz. https://web.archive.org/web/20050114231201/http://edergi.emo.org.tr/index.php?yazi=13&y=2002&s=5) Spor adamları takımlarının ve rakip takımların performanslarını, zayıf ve güçlü yanlarını değerlendirmek, buna göre bir strateji geliştirmek için veri madenciliğinden faydalanıyor.
Birçok sektörde, birçok aktör durmaksızın veri topluyor, bunları analiz edip bilgiye dönüştürüyor, bu bilgiyi kullanarak eyleme geçiyor. Tahmin edileceği gibi veriler ne kadar doğru ve çok kaynaktan beslenmişse, ne kadar ustalıkla analiz edilmişse eylem için o kadar değerli bilgi elde ediliyor.
Veri->Bilgi->Eylem süreci çeşitli veri madenciliği yazılımlarıyla kolaylaştırılıp iyileştirilebilir. Yanal’ın da röportajda belirttiği gibi, “Seyirci gözüyle teknik adamın gözünün arasındaki fark nedir? Hiçbir fark yoktur. Neden? Çünkü teknik adam ancak seyirciden elli tane daha fazla parametreyi aklında tutabilir. İşi olduğu için. Fakat bilimden faydalanan 1500 tane parametreye ulaşıp görebilir. Başarı zaten ayrıntılarda gizlidir.” Ancak her evrede analistlerin rolü temeldir. Alana hakim ve veri madenciliği teknikleri konusunda yetkin bir araştırma ekibi olmadan bilgisayarların yapacakları son derece sınırlıdır. Veri madenciliğinin sonuçları son derece insanidir: Analistin ideolojik yönelimleri, önyargıları, bilgi düzeyi vb. etkenlerce belirlenir.
Eleştiriler
Ülkemizde yaşanabilecek sorunları önceden görebilmek adına, 11 Eylül’ün sonrasında veri madenciliği faaliyetlerine hız veren ABD hükümetlerine yöneltilen eleştirilere göz atmakta fayda var (Guzik, 2009).
Daha 11 Eylül saldırıları birinci yılını doldurmadan The USA Today, NSA’nın teröristlerin davranış örüntülerini tespit etmek amacıyla tüm ABD vatandaşlarının kayıtlarını, telefon konuşmalarını depoladığını yazıyordu. ABD hükümetleri terörizmi engellemek amacıyla MATRIX, TIA, ADVISE1, TALON, ATS vb adlarda programlar başlattılar. Bu programlar ülkelerin terörizmle mücadele stratejilerinde önemli bir değişikliğe de işaret ediyordu: özne temelli analizden örüntü temelli analize geçiliyordu. Özne temelli analiz, şüpheli kişilerin bağlantıları üzerinde bir analizdir. Örüntü temelli analiz ise bilgiyi istatistiksel ve tümevarımsal işlemlerden elde eder. Şüpheden çok öngörüsel bir karakteri vardır. Dolayısıyla telefon dinlemeleri şüphe temelli analizken, The USA Today’in haberindeki gözetim örüntülerden yola çıkar.
Yukarıda belirttiğim gibi veri madenciliği tamamen nesnel bir süreç değildir, öznel etkenler de işin içindedir. Dolayısıyla ABD’nin terörizmle mücadelesinde oluşan riskli terörist profilinin temelinde Arap, Müslüman ve Güney Amerika kökenli vatandaşların olması şaşırtıcı değildir. Etnik köken, din ya da doğum yeri nedeniyle bu profilde yer alan insanlar normalden çok daha yoğun bir takibe maruz kaldılar, uçak yolculuklarında daha çok sorun yaşadılar ve polis tarafından daha çok şüpheli muamelesi gördüler.
Etnik köken, din ya da doğum yeri bilgisinin terörizm riskini hesaplayan algoritmalarda bir parametre olarak yer alması analizlerde toplumun bu kesimlerinin daha yüksek risk değerlerine sahip olmasına neden oluyor. Böylece insanlar yaptıklarından dolayı değil insan haklarına aykırı olarak kendilerinin belirleyemeyeceği etkenler yüzünden dezavantajlı bir konuma itiliyorlar. Oysa ABD’de 11 Eylül öncesinin en büyük terör eylemi 1995 yılında Oklahama City’de beyazlar tarafından gerçekleştirilmiştir. Ama bu eylem beyazlara karşı bir ayrımcılığa neden olmadığı gibi saldırganlar beyaz toplumun sapkın bireyleri olarak değerlendirilmişlerdir (age).
Peki haksız yere ayrımcılığa maruz kalan insanların devlet karşıtı faaliyetlere yönelme güdüsü artmaz mı? ABD’nin terörizmle mücadele programı, terörizmi önlerken, toplumsal barışa zarar vermiyor mu?
Fişlemeye meraklı ülkemizde benzer bir veri madenciliği çalışması yapıldığını (belki de uygulanıyordur) düşünelim…
Türkiye’de Arapların ve Güney Amerikalıların yerine kimlerin geçeceğini tahmin etmek zor değil!
Bu nedenle, insanlık yararına kullanıldığında çok önemli başarılar elde edebilecek veri madenciliği kontrol edilemediğinde ürkütücüdür. Büyük veri üzerinde analiz yapan tüm şirketlerin ve kamu kurumlarının, özerk kamu kurumları tarafından denetlenmesi gerekir.
Fakat şu anki toplumsal koşullarda gelecek konusunda umutlu değilim. İnsanlar, “ben iyi bir vatandaşım, saklayacak bir şeyim yok” ya da “devlet zaten beni fişlemiş, daha ne de çekineceğim” demekten vazgeçip kendilerinden zorla alınan ya da gönüllü olarak saçtıkları verileri sorgulamaya başlamadıkça gelecek pek parlak görünmüyor…
Şimdilik tek çare, bundan rahatsız olanların TOR (https://www.torproject.org/download/download) gibi yazılımlar kullanması…
Kaynaklar
1) Bramer, M. (2013). Principles of data mining. Springer.
2) Guzik, K. (2009). Discrimination by Design: predictive data mining as security practice in the United States ’’war on terrorism’. Surveillance & Society, 5(4).
3) Hammergren, T. C., & Simon, A. R. (2009). Data Warehousing for Dummies.
4) Larose, D. T. (2005). Discovering knowledge in data: an introduction to data mining. John Wiley & Sons.
5) Westphal, C. (2008). Data Mining for Intelligence, Fraud & Criminal Detection: Advanced Analytics & Information Sharing Technologies. CRC Press.



{kind=link}